 Malisiewicz, Ph.D.")
|
My research lies at the intersection of 3D Computer Vision (SLAM) and Deep Learning. My favorite applications are AR and Robotics, which both require a high degree of spatial awareness. My work has been published at top research conferences (CVPR, ICCV, and ECCV). Curriculum Vitae – Google Scholar – bio.txtGithub – Twitter – LinkedIn Email: tomaszxkxkxk@csail.mit.edu | tomasz.malisiewiczxkxkxk@gmail.com |
|
|
I am a Research Scientist Manager at Meta Reality Labs. We work on the next generation of wearable computing. |
|
|
From 2020 to 2021, I was a Senior Research Scientist at Amazon Robotics AI. I worked on Computer Vision and Robotics projects related to automation within Amazon's Fulfillment Centers. |
|
|
From 2015 to 2020, I was a Principal Engineer at Magic Leap, Inc. My applied research focused on applications of Deep Learning to SLAM and real-time 3D reconstruction. I advised Daniel DeTone and Paul-Edouard Sarlin (now a Ph.D. Student at ETH Zurich). See publications below. |
|
|
From 2013 to 2015, I was a Co-Founder of VISION.AI, LLC. Our team delivered custom object detection and machine learning algorithms over a REST API. See our Kickstarter video: VMX Project: Computer Vision for Everyone. |

|
From 2011 to 2013, I was a Postdoctoral Fellow at MIT CSAIL, where I worked with Antonio Torralba and his lab on a wide array of topics like real-time object detection, dataset bias, transfer learning, and feature visualization. |

|
From 2005 to 2011, I was a Ph.D. student in Robotics at Carnegie Mellon University, where I worked under the supervision of Alexei (Alyosha) Efros on examplar-based techniques, style-transfer, object detection, and contextual reasoning. My research was funded by an NSF Graduate Research Fellowship. |

|
During the summers of 2008 and 2009, I worked on large-scale Computer Vision problems at Google Research as a Software Engineering Intern. |
Recent Invited Talks
06/14/2020 Seattle, WA. CVPR 2020. Joint Workshop on Long-Term Visual Localization, Visual Odometry and Geometric and Learning-based SLAM. Deep Visual SLAM Frontends: SuperPoint, SuperGlue, and SuperMaps. [Workshop Link] [PDF Slides] [YouTube]
11/02/2019 Seoul, South Korea. ICCV 2019. 2nd Workshop on Deep Learning for Visual SLAM. Learning Deep Visual SLAM Frontends: SuperPoint++.[Workshop Link] [PDF Slides]
10/16/2018 New York, NY. Butterfly Network. Learning Deep Convolutional Frontends for Visual SLAM.
10/15/2018 New York, NY. Cornell Tech Pixel Cafe. Learning Deep Convolutional Frontends for Visual SLAM.
09/24/2018 Warsaw, Poland. Warsaw University of Technology. Data Science Warsaw #40 AR & SLAM. Learning Deep Convolutional Frontends for Visual SLAM. [Workshop Link]
09/14/2018 Munich, Germany. ECCV 2018. Geometry Meets Deep Learning Workshop. Learning Deep Convolutional Frontends for Visual SLAM.[Workshop Link] [PDF Slides]
06/18/2018 Salt Lake City, UT. CVPR 2018. 1st Workshop on Deep Learning for Visual SLAM. SuperPoint: Self-Supervised Interest Point Detection and Description. [PDF Slides] [Keynote Slides]
[Older Talks]
Publications
2020


|
SuperGlue: Learning Feature Matching with Graph Neural Networks
In CVPR, 2020. (Oral Presentation) (Internship Project) [Abstract] [Paper] [Project Page] [Github] [BibTeX] 1st place in three CVPR 2020 competitions (see Paul's mini-talks) This paper introduces SuperGlue, a neural network that matches two sets of local features by jointly finding correspondences and rejecting non-matchable points. Assignments are estimated by solving a differentiable optimal transport problem, whose costs are predicted by a graph neural network. We introduce a flexible context aggregation mechanism based on attention, enabling SuperGlue to reason about the underlying 3D scene and feature assignments jointly. Compared to traditional, hand-designed heuristics, our technique learns priors over geometric transformations and regularities of the 3D world through end-to-end training from image pairs. SuperGlue outperforms other learned approaches and achieves state-of-the-art results on the task of pose estimation in challenging real-world indoor and outdoor environments. The proposed method performs matching in real-time on a modern GPU and can be readily integrated into modern SfM or SLAM systems. The code and trained weights are publicly available at https://github.com/magicleap/SuperGluePretrainedNetwork.
@inproceedings{sarlin20superglue,
title = {SuperGlue: Learning Feature Matching with Graph Neural Networks},
author = {Paul-Edouard Sarlin and
Daniel DeTone and
Tomasz Malisiewicz and
Andrew Rabinovich},
booktitle = {CVPR},
year = {2020},
}
|
2019
 |
Deep ChArUco: Dark ChArUco Marker Pose Estimation In CVPR, 2019. [Abstract] [Paper] [Video] [Poster] [BibTeX] ChArUco boards are used for camera calibration, monocular pose estimation, and pose verification in both robotics and augmented reality. Such fiducials are detectable via traditional computer vision methods (as found in OpenCV) in well-lit environments, but classical methods fail when the lighting is poor or when the image undergoes extreme motion blur. We present Deep ChArUco, a real-time pose estimation system which combines two custom deep networks, ChArUcoNet and RefineNet, with the Perspective-n-Point (PnP) algorithm to estimate the marker's 6DoF pose. ChArUcoNet is a two-headed marker-specific convolutional neural network (CNN) which jointly outputs ID-specific classifiers and 2D point locations. The 2D point locations are further refined into subpixel coordinates using RefineNet. Our networks are trained using a combination of auto-labeled videos of the target marker, synthetic subpixel corner data, and extreme data augmentation. We evaluate Deep ChArUco in challenging low-light, high-motion, high-blur scenarios and demonstrate that our approach is superior to a traditional OpenCV-based method for ChArUco marker detection and pose estimation.
@inproceedings{Hu_2019_CVPR,
title = {Deep ChArUco: Dark ChArUco Marker Pose Estimation},
author = {Hu, Danying and
DeTone, Daniel and
Malisiewicz, Tomasz},
booktitle = {CVPR},
year = {2019}
}
|

|
Learning Data-Adaptive Interest Points through Epipolar Adaptation
In CVPR Workshops, 2019. (Internship Project) [Abstract] [Paper] [BibTeX] Interest point detection and description have been cornerstones of many computer vision applications. Handcrafted methods like SIFT and ORB focus on generic interest points and do not lend themselves to data-driven adaptation. Recent deep learning models are generally either supervised using expensive 3D information or with synthetic 2D transformations such as homographies that lead to improper handling of nuisance features such as occlusion junctions. In this paper, we propose an alternative form of supervision that leverages the epipolar constraint associated with the fundamental matrix. This approach brings useful 3D information to bear without requiring full depth estimation of all points in the scene. Our proposed approach, Epipolar Adaptation, fine-tunes both the interest point detector and descriptor using a supervision signal provided by the epipolar constraint. We show that our method can improve upon the baseline in a target dataset annotated with epipolar constraints, and the epipolar adapted models learn to remove correspondence involving occlusion junctions correctly.
@inproceedings{Yang_2019_CVPR_Workshops,
title = {Learning Data-Adaptive Interest Points through Epipolar Adaptation},
author = {Yang, Guandao and
Malisiewicz, Tomasz and
Belongie, Serge},
booktitle = {CVPR Workshops},
year = {2019}
}
|
2018
 |
Self-Improving Visual Odometry arXiv Technical Report. December, 2018. [Abstract] [Paper] [BibTeX] We propose a self-supervised learning framework that uses unlabeled monocular video sequences to generate large-scale supervision for training a Visual Odometry (VO) frontend, a network which computes pointwise data associations across images. Our self-improving method enables a VO frontend to learn over time, unlike other VO and SLAM systems which require time-consuming hand-tuning or expensive data collection to adapt to new environments. Our proposed frontend operates on monocular images and consists of a single multi-task convolutional neural network which outputs 2D keypoints locations, keypoint descriptors, and a novel point stability score. We use the output of VO to create a self-supervised dataset of point correspondences to retrain the frontend. When trained using VO at scale on 2.5 million monocular images from ScanNet, the stability classifier automatically discovers a ranking for keypoints that are not likely to help in VO, such as t-junctions across depth discontinuities, features on shadows and highlights, and dynamic objects like people. The resulting frontend outperforms both traditional methods (SIFT, ORB, AKAZE) and deep learning methods (SuperPoint and LF-Net) in a 3D-to-2D pose estimation task on ScanNet.
@article{detone2018self,
title={Self-improving visual odometry},
author={DeTone, Daniel and
Malisiewicz, Tomasz and
Rabinovich, Andrew},
journal={arXiv preprint arXiv:1812.03245},
year={2018}
}
|

|
SuperPoint: Self-Supervised Interest Point Detection and Description In CVPR Deep Learning for Visual SLAM Workshop, 2018. (Oral Presentation) [Abstract] [Paper] [Github] [Presentation] [BibTeX] This paper presents a self-supervised framework for training interest point detectors and descriptors suitable for a large number of multiple-view geometry problems in computer vision. As opposed to patch-based neural networks, our fully-convolutional model operates on full-sized images and jointly computes pixel-level interest point locations and associated descriptors in one forward pass. We introduce Homographic Adaptation, a multi-scale, multi-homography approach for boosting interest point detection repeatability and performing cross-domain adaptation (e.g., synthetic-to-real). Our model, when trained on the MS-COCO generic image dataset using Homographic Adaptation, is able to repeatedly detect a much richer set of interest points than the initial pre-adapted deep model and any other traditional corner detector. The final system gives rise to state-of-the-art homography estimation results on HPatches when compared to LIFT, SIFT and ORB.
@inproceedings{detone2018superpoint,
title={Superpoint: Self-supervised interest point detection and description},
author={DeTone, Daniel and
Malisiewicz, Tomasz and
Rabinovich, Andrew},
booktitle={CVPR Deep Learning for Visual SLAM Workshop},
year={2018}
}
|
2017
 |
RoomNet: End-to-End Room Layout Estimation In ICCV, 2017. [Abstract] [Paper] [BibTeX] This paper focuses on the task of room layout estimation from a monocular RGB image. Prior works break the problem into two sub-tasks: semantic segmentation of floor, walls, ceiling to produce layout hypotheses, followed by an iterative optimization step to rank these hypotheses. In contrast, we adopt a more direct formulation of this problem as one of estimating an ordered set of room layout keypoints. The room layout and the corresponding segmentation is completely specified given the locations of these ordered keypoints. We predict the locations of the room layout keypoints using RoomNet, an end-to-end trainable encoder-decoder network. On the challenging benchmark datasets Hedau and LSUN, we achieve state-of-the-art performance along with 200x to 600x speedup compared to the most recent work. Additionally, we present optional extensions to the RoomNet architecture such as including recurrent computations and memory units to refine the keypoint locations under the same parametric capacity.
@inproceedings{lee2017roomnet,
title={Roomnet: End-to-end room layout estimation},
author={Lee, Chen-Yu and
Badrinarayanan, Vijay and
Malisiewicz, Tomasz and
Rabinovich, Andrew},
booktitle={ICCV},
year={2017}
}
|

|
Toward Geometric DeepSLAM
arXiv Technical Report. July, 2017. [Abstract] [Paper] [BibTeX] We present a point tracking system powered by two deep convolutional neural networks. The first network, MagicPoint, operates on single images and extracts salient 2D points. The extracted points are "SLAM-ready" because they are by design isolated and well-distributed throughout the image. We compare this network against classical point detectors and discover a significant performance gap in the presence of image noise. As transformation estimation is more simple when the detected points are geometrically stable, we designed a second network, MagicWarp, which operates on pairs of point images (outputs of MagicPoint), and estimates the homography that relates the inputs. This transformation engine differs from traditional approaches because it does not use local point descriptors, only point locations. Both networks are trained with simple synthetic data, alleviating the requirement of expensive external camera ground truthing and advanced graphics rendering pipelines. The system is fast and lean, easily running 30+ FPS on a single CPU.
@article{detone2017toward,
title={Toward geometric deep SLAM},
author={DeTone, Daniel and
Malisiewicz, Tomasz and
Rabinovich, Andrew},
journal={arXiv preprint arXiv:1707.07410},
year={2017}
}
|
2016
 |
Deep Cuboid Detection: Beyond 2D Bounding Boxes arXiv Technical Report. November, 2016. (Internship Project) [Abstract] [Paper] [BibTeX] We present a Deep Cuboid Detector which takes a consumer-quality RGB image of a cluttered scene and localizes all 3D cuboids (box-like objects). Contrary to classical approaches which fit a 3D model from low-level cues like corners, edges, and vanishing points, we propose an end-to-end deep learning system to detect cuboids across many semantic categories (e.g., ovens, shipping boxes, and furniture). We localize cuboids with a 2D bounding box, and simultaneously localize the cuboid's corners, effectively producing a 3D interpretation of box-like objects. We refine keypoints by pooling convolutional features iteratively, improving the baseline method significantly. Our deep learning cuboid detector is trained in an end-to-end fashion and is suitable for real-time applications in augmented reality (AR) and robotics.
@article{dwibedi2016deep,
title={Deep cuboid detection: Beyond 2d bounding boxes},
author={Dwibedi, Debidatta and
Malisiewicz, Tomasz and
Badrinarayanan, Vijay and
Rabinovich, Andrew},
journal={arXiv preprint arXiv:1611.10010},
year={2016}
}
|
 |
Deep Image Homography Estimation
In RSS Workshop on Limits and Potentials of Deep Learning in Robotics, 2016. (Oral Presentation) [Abstract] [Paper] [BibTeX] We present a deep convolutional neural network for estimating the relative homography between a pair of images. Our feed-forward network has 10 layers, takes two stacked grayscale images as input, and produces an 8 degree of freedom homography which can be used to map the pixels from the first image to the second. We present two convolutional neural network architectures for HomographyNet: a regression network which directly estimates the real-valued homography parameters, and a classification network which produces a distribution over quantized homographies. We use a 4-point homography parameterization which maps the four corners from one image into the second image. Our networks are trained in an end-to-end fashion using warped MS-COCO images. Our approach works without the need for separate local feature detection and transformation estimation stages. Our deep models are compared to a traditional homography estimator based on ORB features and we highlight the scenarios where HomographyNet outperforms the traditional technique. We also describe a variety of applications powered by deep homography estimation, thus showcasing the flexibility of a deep learning approach.
@article{detone2016deep,
title={Deep image homography estimation},
author={DeTone, Daniel and
Malisiewicz, Tomasz and
Rabinovich, Andrew},
booktitle = {RSS Workshop on Limits and Potentials of Deep Learning in Robotics},
year={2016}
}
|
 |
Visualizing object detection features
International Journal of Computer Vision (IJCV), September 2016. [Abstract] [Paper] [BibTeX] We introduce algorithms to visualize feature spaces used by object detectors. Our method works by inverting a visual feature back to multiple natural images.We found that these visualizations allow us to analyze object detection systems in new ways and gain new insight into the detector’s failures. For example, when we visualize the features for high scoring false alarms, we discovered that, although they are clearly wrong in image space, they often look deceptively similar to true positives in feature space. This result suggests that many of these false alarms are caused by our choice of feature space, and supports that creating a better learning algorithm or building bigger datasets is unlikely to correct these errors without improving the features. By visualizing feature spaces, we can gain a more intuitive understanding of recognition systems.
@article{vondrick2016visualizing,
title={Visualizing object detection features},
author={Vondrick, Carl and
Khosla, Aditya and
Pirsiavash, Hamed and
Malisiewicz, Tomasz and
Torralba, Antonio},
journal={International Journal of Computer Vision},
volume={119},
number={2},
pages={145--158},
year={2016}
}
|
2014
 |
Exemplar Network: A Generalized Mixture Model
In ICPR, 2014. [Abstract] [Paper] [BibTeX] We present a non-linear object detector called Exemplar Network. Our model efficiently encodes the space of all possible mixture models, and offers a framework that generalizes recent exemplar-based object detection with monolithic detectors. We evaluate our method on the traffic scene dataset that we collected using onboard cameras, and demonstrate an orientation estimation. Our model has both the interpretability and accessibility necessary for industrial applications. One can easily apply our method to a variety of applications.
@inproceedings{tsuchiya2014exemplar,
title={Exemplar network: A generalized mixture model},
author={Tsuchiya, Chikao and
Malisiewicz, Tomasz and
Torralba, Antonio},
booktitle={ICPR},
year={2014}
}
|
2013
 |
HOGgles: Visualizing Object Detection Features
In ICCV, 2013. (Oral Presentation) [Abstract] [Paper] [Project Page] [Github] [BibTeX] In the Press: [
@inproceedings{vondrick2013hoggles,
title={Hoggles: Visualizing object detection features},
author={Vondrick, Carl and
Khosla, Aditya and
Malisiewicz, Tomasz and
Torralba, Antonio},
booktitle={ICCV},
year={2013}
}
|
2012

|
Undoing the Damage of Dataset Bias
In ECCV, 2012. [Abstract] [Paper] [Project Page] [BibTeX] The presence of bias in existing object recognition datasets is now well-known in the computer vision community. While it remains in question whether creating an unbiased dataset is possible given limited resources, in this work we propose a discriminative framework that directly exploits dataset bias during training. In particular, our model learns two sets of weights: (1) bias vectors associated with each individual dataset, and (2) visual world weights that are common to all datasets, which are learned by undoing the associated bias from each dataset. The visual world weights are expected to be our best possible approximation to the object model trained on an unbiased dataset, and thus tend to have good generalization ability. We demonstrate the effectiveness of our model by applying the learned weights to a novel, unseen dataset, and report superior results for both classification and detection tasks compared to a classical SVM that does not account for the presence of bias. Overall, we find that it is beneficial to explicitly account for bias when combining multiple datasets.
@inproceedings{khosla2012undoing,
title={Undoing the damage of dataset bias},
author={Khosla, Aditya and
Zhou, Tinghui and
Malisiewicz, Tomasz and
Efros, Alexei A and
Torralba, Antonio},
booktitle={ECCV},
year={2012}
}
|

|
A Gaussian
Approximation of Feature Space for Fast Image Similarity
MIT CSAIL Technical Report, 2012. [Abstract] [Paper] [BibTeX] We introduce a fast technique for the robust computation of image similarity. It builds on a re-interpretation of the recent exemplar-based SVM approach, where a linear SVM is trained at a query point and distance is computed as the dot product with the normal to the separating hyperplane. Although exemplar-based SVM is slow because it requires a new training for each exemplar, the latter approach has shown robustness for image retrieval and object classification, yielding state-of-the-art performance on the PASCAL VOC 2007 detection task despite its simplicity. We re-interpret it by viewing the SVM between a single point and the set of negative examples as the computation of the tangent to the manifold of images at the query. We show that, in a high-dimensional space such as that of image features, all points tend to lie at the periphery and that they are usually separable from the rest of the set. We then use a simple Gaussian approximation to the set of all images in feature space, and fit it by computing the covariance matrix on a large training set. Given the covariance matrix, the computation of the tangent or normal at a point is straightforward and is a simple multiplication by the inverse covariance. This allows us to dramatically speed up image retrieval tasks, going from more than ten minutes to a single second. We further show that our approach is equivalent to feature-space whitening and has links to image saliency.
@article{gharbi2012gaussian)
title={A Gaussian approximation of feature space for fast image similarity},
author={Gharbi, Michael and
Malisiewicz, Tomasz and
Paris, Sylvain and
Durand, Fr{\'e}do},
year={2012}
}
|
2011

|
Exemplar-based Representations for Object Detection, Association and Beyond
Carnegie Mellon University Ph.D. Thesis, 2011. [Abstract] [Paper] [BibTeX] Recognizing and reasoning about the objects found in an image is one of the key problems in computer vision. This thesis is based on the idea that in order to understand a novel object, it is often not enough to recognize the object category it belongs to (i.e., answering “What is this?”). We argue that a more meaningful interpretation can be obtained by linking the input object with a similar representation in memory (i.e., asking “What is this like?”). In this thesis, we present a memory-based system for recognizing and interpreting objects in images by establishing visual associations between an input image and a large database of object exemplars. These visual associations can then be used to predict properties of the novel object which cannot be deduced solely from category membership (e.g., which way is it facing? what is its segmentation? is there a person sitting on it?). Part I of this thesis is dedicated to exemplar representations and algorithms for creating visual associations. We propose Local Distance Functions and Exemplar-SVMs, which are trained separately for each exemplar and allow an instance-specific notion of visual similarity. We show that an ensemble of Exemplar-SVMs performs competitively to state-of-the-art on the PASCAL VOC object detection task. In Part II, we focus on the advantages of using exemplars over a purely category-based approach. Because Exemplar-SVMs show good alignment between detection windows and their associated exemplars, we show that it is possible to transfer any available exemplar meta-data (segmentation, geometric structure, 3D model, etc.) directly onto the detections, which can then be used as part of overall scene understanding. Finally, we construct a Visual Memex, a vast graph over exemplars encoding both visual as well as spatial relationships, and apply it to an object prediction task. Our results show that exemplars provide a better notion of object context than category-based approaches.
@book{malisiewicz2011exemplar,
title={Exemplar-based representations for object detection, association and beyond},
author={Malisiewicz, Tomasz},
year={2011},
publisher={Carnegie Mellon University}
}
|

|
Data-driven Visual
Similarity for Cross-domain Image Matching
In SIGGRAPH ASIA, 2011. (Oral Presentation) [Abstract] [Paper] [Project Page] [BibTeX] In the Press: [ The goal of this work is to find visually similar images even if they appear quite different at the raw pixel level. This task is particularly important for matching images across visual domains, such as photos taken over different seasons or lighting conditions, paintings, hand-drawn sketches, etc. We propose a surprisingly simple method that estimates the relative importance of different features in a query image based on the notion of "data-driven uniqueness". We employ standard tools from discriminative object detection in a novel way, yielding a generic approach that does not depend on a particular image representation or a specific visual domain. Our approach shows good performance on a number of difficult cross-domain visual tasks e.g., matching paintings or sketches to real photographs. The method also allows us to demonstrate novel applications such as Internet re-photography, and painting2gps.
@inproceedings{shrivastava2011data,
title={Data-driven visual similarity for cross-domain image matching},
author={Shrivastava, Abhinav and
Malisiewicz, Tomasz and
Gupta, Abhinav and
Efros, Alexei A},
booktitle={SIGGRAPH Asia},
year={2011}
}
|

|
Ensemble of
Exemplar-SVMs for Object Detection and Beyond
In ICCV, 2011. [Abstract] [Paper] [Project Page] [Github] [BibTeX] This paper proposes a conceptually simple but surprisingly powerful method which combines the effectiveness of a discriminative object detector with the explicit correspondence offered by a nearest-neighbor approach. The method is based on training a separate linear SVM classifier for every exemplar in the training set. Each of these Exemplar-SVMs is thus defined by a single positive instance and millions of negatives. While each detector is quite specific to its exemplar, we empirically observe that an ensemble of such Exemplar-SVMs offers surprisingly good generalization. Our performance on the PASCAL VOC detection task is on par with the much more complex latent part-based model of Felzenszwalb et al., at only a modest computational cost increase. But the central benefit of our approach is that it creates an explicit association between each detection and a single training exemplar. Because most detections show good alignment to their associated exemplar, it is possible to transfer any available exemplar meta-data (segmentation, geometric structure, 3D model, etc.) directly onto the detections, which can then be used as part of overall scene understanding.
@inproceedings{malisiewicz2011ensemble,
title={Ensemble of exemplar-svms for object detection and beyond},
author={Malisiewicz, Tomasz and
Gupta, Abhinav and
Efros, Alexei A},
booktitle={ICCV},
year={2011}
}
|
2009

|
Beyond Categories: The
Visual Memex Model for Reasoning About Object Relationships
In NIPS, 2009. [Abstract] [Paper] [Project Page] [BibTeX] The use of context is critical for scene understanding in computer vision, where the recognition of an object is driven by both local appearance and the object's relationship to other elements of the scene (context). Most current approaches rely on modeling the relationships between object categories as a source of context. In this paper we seek to move beyond categories to provide a richer appearance-based model of context. We present an exemplar-based model of objects and their relationships, the Visual Memex, that encodes both local appearance and 2D spatial context between object instances. We evaluate our model on Torralba's proposed Context Challenge against a baseline category-based system. Our experiments suggest that moving beyond categories for context modeling appears to be quite beneficial, and may be the critical missing ingredient in scene understanding systems.
@inproceedings{malisiewicz2009beyond,
title={Beyond categories: The visual memex model for reasoning about object relationships},
author={Malisiewicz, Tomasz and
Efros, Alexei a.},
booktitle={NIPS},
year={2009}
}
|
2008
 |
Recognition by Association via Learning Per-exemplar Distances
In CVPR, 2008. [Abstract] [Paper] [Project Page + Code] [BibTeX] We pose the recognition problem as data association. In this setting, a novel object is explained solely in terms of a small set of exemplar objects to which it is visually similar. Inspired by the work of Frome et al., we learn separate distance functions for each exemplar; however, our distances are interpretable on an absolute scale and can be thresholded to detect the presence of an object. Our exemplars are represented as image regions and the learned distances capture the relative importance of shape, color, texture, and position features for that region. We use the distance functions to detect and segment objects in novel images by associating the bottom-up segments obtained from multiple image segmentations with the exemplar regions. We evaluate the detection and segmentation performance of our algorithm on real-world outdoor scenes from the LabelMe dataset and also show some promising qualitative image parsing results.
@inproceedings{malisiewicz2008recognition,
title={Recognition by association via learning per-exemplar distances},
author={Malisiewicz, Tomasz and
Efros, Alexei A},
booktitle={CVPR},
year={2008}
}
|
2007
 |
Improving Spatial Support
for Objects via Multiple Segmentations
In BMVC, 2007. (Oral Presentation) [Abstract] [Paper] [Project Page] [BibTeX] Sliding window scanning is the dominant paradigm in object recognition research today. But while much success has been reported in detecting several rectangular-shaped object classes (i.e. faces, cars, pedestrians), results have been much less impressive for more general types of objects. Several researchers have advocated the use of image segmentation as a way to get a better spatial support for objects. In this paper, our aim is to address this issue by studying the following two questions: 1) how important is good spatial support for recognition? 2) can segmentation provide better spatial support for objects? To answer the first, we compare recognition performance using ground-truth segmentation vs. bounding boxes. To answer the second, we use the multiple segmentation approach to evaluate how close can real segments approach the ground-truth for real objects, and at what cost. Our results demonstrate the importance of finding the right spatial support for objects, and the feasibility of doing so without excessive computational burden.
@inproceedings{malisiewicz-bmvc07,
Title = {Improving Spatial Support for Objects via Multiple Segmentations},
Author = {Tomasz Malisiewicz and
Alexei A. Efros},
Booktitle = {British Machine Vision Conference (BMVC)},
Month = {September},
Year = {2007}
}
|
2005
 |
Registration of Multiple
Range Scans as a Location Recognition Problem:
Hypothesis Generation, Refinement, and Verification
In 3DIM, 2005. [Abstract] [Paper] [BibTeX] This paper addresses the following version of the multiple range scan registration problem. A scanner with an associated intensity camera is placed at a series of locations throughout a large environment; scans are acquired at each location. The problem is to decide automatically which scans overlap and to estimate the parameters of the transformations aligning these scans. Our technique is based on (1) detecting and matching keypoints — distinctive locations in range and intensity images, (2) generating and refining a transformation estimate from each keypoint match, and (3) deciding if a given refined estimate is correct. While these steps are familiar, we present novel approaches to each. A new range keypoint technique is presented that uses spin images to describe holes in smooth surfaces. Intensity keypoints are detected using multiscale filters, described using intensity gradient histograms, and backprojected to form 3D keypoints. A hypothesized transformation is generated by matching a single keypoint from one scan to a single keypoint from another, and is refined using a robust form of the ICP algorithm in combination with controlled region growing. Deciding whether a refined transformation is correct is based on three criteria: alignment accuracy, visibility, and a novel randomness measure. Together these three steps produce good results in test scans of the Rensselaer campus.
@inproceedings{king2005registration,
title={Registration of multiple range scans as a location recognition problem: Hypothesis generation, refinement and verification},
author={King, Bradford J and
Malisiewicz, Tomasz
and Stewart, Charles V and
Radke, Richard J},
booktitle={Fifth International Conference on 3-D Digital Imaging and Modeling (3DIM'05)},
pages={180--187},
year={2005}
}
|
Misc Manuscripts
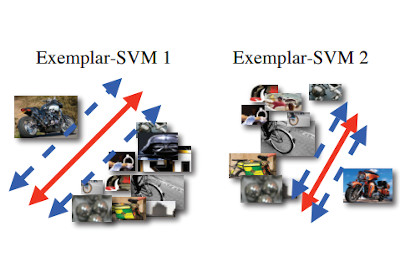 |
Exemplar-SVMs for Visual
Object Detection, Label Transfer and Image Retrieval
ICML 2012 Invited Applications Talk + Extended Abstract, 2012. [Paper] |
 |
Detecting Objects via
Multiple Segmentations and Latent Topic Models
Carnegie Mellon University Tech Report, 2006. [Paper] |
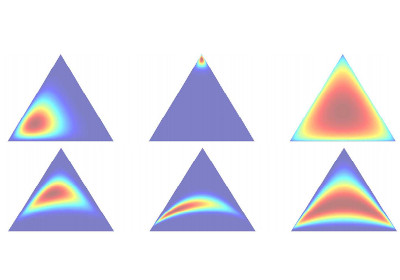 |
Fitting a Hierarchical
Logistic Normal Distribution
Carnegie Mellon University Tech Report, 2006. [Paper] |
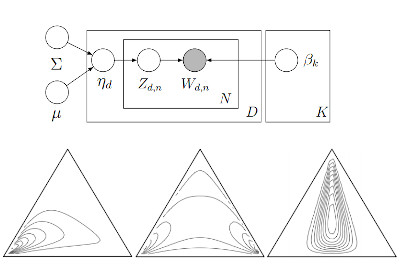 |
Correlated Topic Model Details
Carnegie Mellon University Tech Report, 2006. [Paper] |
 |
Modeling Relativistic
Muons in Electromagnetic Storage Rings via Object
Oriented Techniques
Brookhaven National Laboratory Technical Report, 2002. [Paper] |